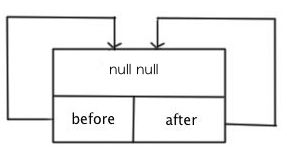
privatestaticclassEntry<K,V>extendsHashMap.Entry<K,V>{// These fields comprise the doubly linked list used for iteration.Entry<K,V>before,after;Entry(inthash,Kkey,Vvalue,HashMap.Entry<K,V>next){super(hash,key,value,next);}/** * Removes this entry from the linked list. */privatevoidremove(){before.after=after;after.before=before;}/** * Inserts this entry before the specified existing entry in the list. */privatevoidaddBefore(Entry<K,V>existingEntry){after=existingEntry;before=existingEntry.before;before.after=this;after.before=this;}/** * This method is invoked by the superclass whenever the value * of a pre-existing entry is read by Map.get or modified by Map.set. * If the enclosing Map is access-ordered, it moves the entry * to the end of the list; otherwise, it does nothing. */voidrecordAccess(HashMap<K,V>m){LinkedHashMap<K,V>lm=(LinkedHashMap<K,V>)m;if(lm.accessOrder){lm.modCount++;remove();addBefore(lm.header);}}voidrecordRemoval(HashMap<K,V>m){remove();}}
privateabstractclassLinkedHashIterator<T>implementsIterator<T>{Entry<K,V>nextEntry=header.after;Entry<K,V>lastReturned=null;/** * The modCount value that the iterator believes that the backing * List should have. If this expectation is violated, the iterator * has detected concurrent modification. */intexpectedModCount=modCount;publicbooleanhasNext(){returnnextEntry!=header;}publicvoidremove(){if(lastReturned==null)thrownewIllegalStateException();if(modCount!=expectedModCount)thrownewConcurrentModificationException();LinkedHashMap.this.remove(lastReturned.key);lastReturned=null;expectedModCount=modCount;}Entry<K,V>nextEntry(){if(modCount!=expectedModCount)thrownewConcurrentModificationException();if(nextEntry==header)thrownewNoSuchElementException();Entry<K,V>e=lastReturned=nextEntry;nextEntry=e.after;returne;}}